Поисковые системы Интернет можно назвать связующим звеном между пользователем и информацией в Интернет. Именно они (поисковики) собирают, обрабатывают и отдают информацию пользователю по сделанному запросу. Именно от их алгоритмов зависит актуальность, правдивость, подлинность получаемой в выдаче информации.
Вопрос работы поисковых систем является утилитарным и для создания сайта не имеет практического значения. Однако, понимание принципа работы того или иного поисковика, могут помочь в продвижении сайта по выдаче этого поисковика.
Вопрос, что такое поисковик не корректный. Более корректно, говорить поисковая система интеренет. Поисковиком принято называть, робота (роботов) поисковой системы, осуществляющего обход и сканирование сайтов открытых для обхода в Интернет.
Поисковые системы интернет это набор программ и технических возможностей, объединенных для генерации контента выдачи по поисковому запросу пользователя.
Программы поисковой системы выполняют три базовые задачи, чаще с подзадачами:
Нужно понимать, все поисковые системы интернет, для выполнения этих трех задач, имеют не три, а десятки программ. Все они работают во взаимосвязи, но не делают лишь одного, они НЕ создают контент, а генерируют его из чужого контента. С философской точки зрения, выдача поисковой системы это веб-страница чужого контента, позаимствованного с десятка других сайтов. Всё бы было честно, если бы они эти страницы не монетизировали.
Кроме программных средств, любая ПС (поисковая система) имеет технические средства. Это реальные сервера разбросанные по всему миру или по всей стране. Еще раз акцентирую, сервера ПС не хранят сканы всех сайтов и не отдают в выдачу сайты со своих серверов. Хранят они только индексы веб-ресурсов, в том числе сайтов.
В отличие от каталогов сайтов, поисковые системы интернет это НЕ стационарные хранилища информации, а симбиоз нескольких программ и технических средств, позволяющих сканировать сайты в Интернет, составлять индекс сайта по своим алгоритмам и отдавать список соответствующих (релевантных) сайтов по запросу пользователя.
Вся работа search engine (поисковых систем), осуществляется по уникальным программам, которые мы знаем, поисковые алгоритмы. Суть этих программ скрыта за «семью печатями», а до нас доводят лишь общие правила новых алгоритмов.
На всякий случай напомню, что можно называть, но не нужно путать Яндекс и Яндекс.Поиск, а также Google и Google Search. Яндекс и Google это скорее бренды, а Яндекс.Поиск и Google Search это всего лишь, поисковые системы интернет этих «монстров».
Кстати, Google это корпорация «Гугл», Google LLC, созданная в 1998 году 04 сентября в США. Яндекс это компания (РТК — Российская транснациональная компания), созданная в 2000 году.
На примере именно этих компаний более подробно посмотрим работу поисковых систем.
Как я упомянул выше, работа поисковых систем строится на трех базовых этапах:
Сканирование веб-ресурсов, осуществляют поисковые роботы (Spider, Crawler, Bot, Robot). Это специальные программы, которые периодически обходят веб-страницы, формируют из них индекс страниц, возможно, делают скан текста.
Обход страниц осуществляется с определенной периодичностью. Чаще других обходят страницы боты Google. Основанием для обхода являются гиперссылки на страницы. При обходе страниц все встречающиеся ссылки боты фиксируют, из ссылок формируются списки для следующих обходов.
Именно по этому, ссылка на новую страницу сайта с уже проиндексированной страницы ускоряет её индексацию. Также, наличие большого количества мертвых ссылок на сайте, формирует негативный образ сайта, и такой сайт обходится ботами реже. Кроме этого, поисковые роботы обращают внимание на sitemap сайта и используют его, как вспомогательный навигатор для поиска новых ссылок для обхода.
Из всех страниц, которые обходит Bot, формируется база данных поисковой системы. В базе данных находятся все страницы, которые боты «просеяли» через «крупное сито» и посчитали, возможно, интересными для выдачи.
Из этой базы данных, следующая группа программ, формирует индекс поисковой системы — те веб-страницы, которые будут показаны в выдаче.
Индексирование страниц происходит по уникальным алгоритмам поисковых систем. Алгоритмы индексирования часто меняются, особенно у Яндекс, из-за чего индекс поисковика может претерпевать серьезные изменения.
Однако есть базовые элементы структуры сайта, которые долгие годы остаются в алгоритмах попадания в индекс. Это, прежде всего:
Именно из этих элементов создается первый индекс страниц.
Для ранжирования страниц в выдаче, в индекс страниц попадают:
Последняя группа программ, формируют из индекса поисковую выдачу по сделанному поисковому запросу.
Стоит отметить, что, несмотря на заявленные интеллектуальные способности некоторых поисковых алгоритмов, для релевантного поиска своему запросу, нужно пользоваться языком поисковых запросов. Записывая запрос специальным образом, вы более конкретно поясняете боту, что вам нужно.
Но даже без этого, программы ранжирования и выдачи, подбирают по сделанному запросу список веб-ресурсов, которые, по их мнению (алгоритму), соответствуют сделанному запросу. Расстановка ресурсов в списке выдачи называют ранжирование, а соответствие ресурса запросу, называют релевантностью.
Перед, более детальном разговоре об конкретных поисковых системах, пару слов о ранжировании.
Программы ПС, которые формируют выдачу, кроме перечисленных выше элементов поисковой оптимизации, учитывают:
Важно обратить внимание, что алгоритмы поисковых систем разные, отсюда разная выдача по одному и тому же поисковому запросу.
Меня мало интересуют поисковые системы интернет мира, о них вы найдете информацию в других источниках. Здесь базовые поисковики Рунет, которые знает весь мир.
Базовый адрес страницы поиска Google: www.google.ru. Google Search известнейшая поисковая система, запрещенная в Китае (www. google.cn), но остающаяся основным конкурентом Яндекс в России.
Google ведет поиск по всему Интернет, выбирая из своего индекса, наиболее релевантные веб-страницы. Обеспечивают поиск три взаимосвязанных процесса:
Сканирование Интернет осуществляет главный робот Google под названием Googlebot. В его задачи входит обнаружение новых и обновленных страниц для внесения их в базу данных Google.
В задачи программ робота Googledot входят задачи, по которым нужно сканировать сайты, как часто и сколько страниц с каждого сайта.
При каждом сканировании Googlebot составляет список ссылок страниц для сканирования, обходит файлы Sitemap для поиска новых ссылок и набирает ссылки со сканируемых страниц.
Каждая сканируемая страница обрабатывается Googlebot и по этой обработке составляется индекс страницы. В индекс страницы Google входит:
По заданному запросу в поиске Google ищет наиболее подходящие (релевантные) страницы из индекса. Для определения релевантной страницы боты используют факторы релевантности из алгоритмов поисковика Google. Таких факторов более двухсот.
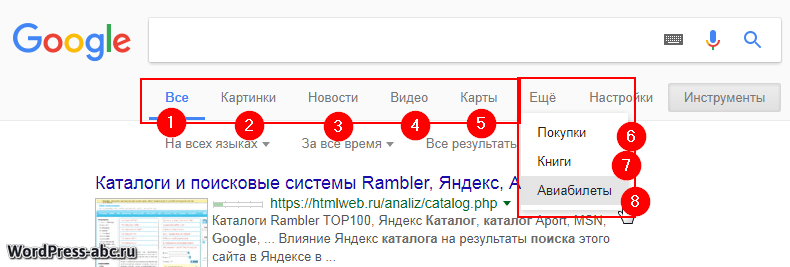
На странице поиска Google мы видит несколько типов поиска:
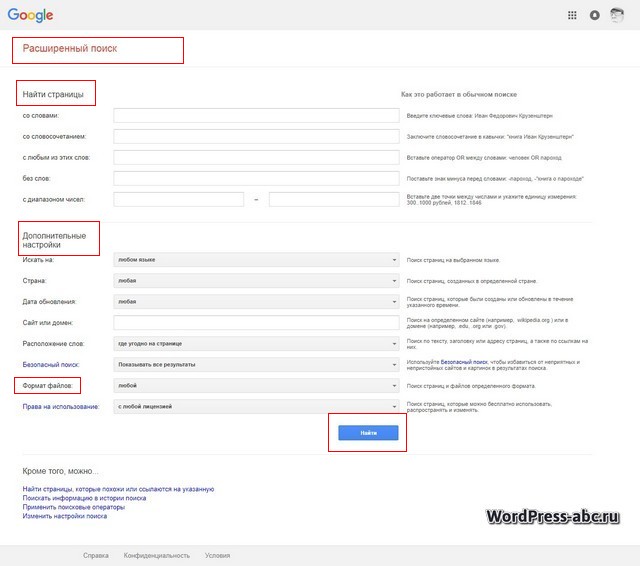
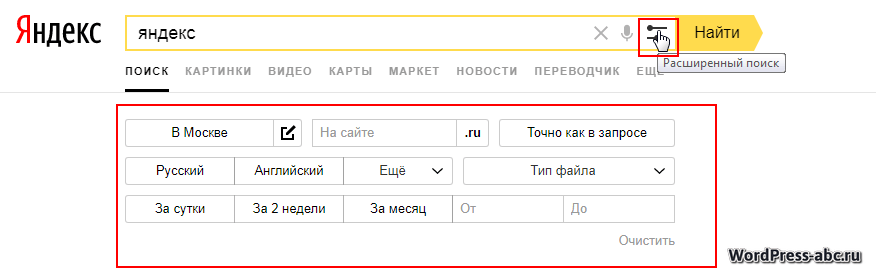
На странице результатов поиска есть кнопки расширенного или лучше сказать специального поиска. Это поиски:
Здесь же поиск можно фильтровать (кнопка Настройки) по:
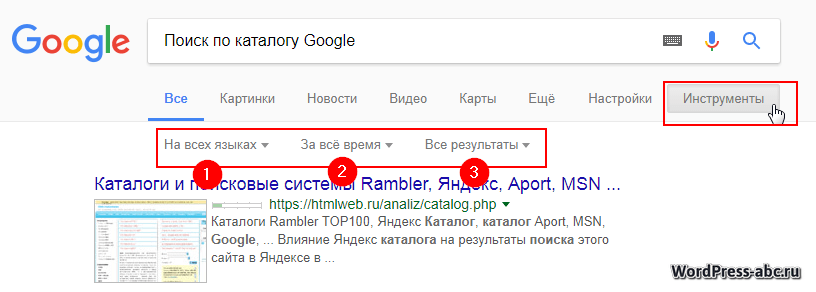
Еще больше сузить фильтр поиска Google поможет кнопка «Инструменты». Здесь можно выбрать язык поиска, время появления информации, и результаты с точным попаданием запроса.
Кроме основного поискового робота Googlebot, система имеет массу других программ более специального сканирования. Общий список их тут //support.google.com/webmasters/answer/1061943?hl=ru. Они могут понадобиться для составления файла robots.txt, мета-тегов robots, команд X-Robots-Tag HTTP. Вот названия нескольких из них (не путать с агентами пользователя):
Основными поисковыми системами Рунет можно назвать: Яндекс, Рамблер, Апорт (Mail). Несомненно, большее внимание заслуживает самый популярный поисковик Рунет — Яндекс.
Страница Яндекс в сети, https://yandex.ru/. Эта страница не является страницей чистого поиска. Страница чистого поиска, очищенная от всей лишней информации тут: https://ya.ru/.
В блоге Яндекс (https://yandex.ru/company/technologies) вы можете найти подробные статьи по каждому этапу работы поисковика Яндекс. Здесь, кратко.
Общий принцип работы поисковой системы Яндекс, можно разделить на два процесса. Первый это обход Интернет поисковыми роботами с целью сбора информации, а точнее сканирования веб-ресурсов. Второй это отдача ответа пользователю, по сделанному поисковому запросу.
Для обхода Интернет в Яндекс «работают» два робота. Основной индексирующий робот «YandexBot» и быстрый робот, который называют «Orange».
Orange ищет в сети самую свежую информацию в Интернет, возраст которой минуты и секунды.
Задачи YandexBot более глобальные. Он обходит Интернет по заданию (спискам ссылок), который формирует робот-планировщик. При обходе YandexBot делает сканы веб-страниц, внося их в свою базу данных.
На следующем этапе, сканы веб-страниц, очищаются от разметки, разбираются, по словам и помещаются в индекс поисковика. У каждого слова есть метка, указывающая, где оно находится в Интернет. Основной слепок документа остается в основной базе Яндекс и удаляется от туда, только после удаления веб-страницы с сайта.
Индекс поиска Яндекс это данные про тип документа, его кодировка, язык, а также сохраненные копии документа вместе составляют поисковую базу.
Поиск Яндекс это часть документов из поисковой базы, очищенных от спама, дублей и другого мусора.
По сделанному запросу Яндекс ищет в своей базе данных подходящие слова (словоформы). У каждого слова в базе есть указатель, на какой веб-странице это слово «лежит».
Все найденные результаты Яндекс ранжирует по своему алгоритму и отдает пользователю в виде списка веб-ресурсов с заголовком, ссылкой и описанием.
Стоит отметить, что основной обход (поиск «пакетами») происходит в основном ночью, 2-3 раза в неделю. Робот Orange работает в режиме реального времени.
У Яндекс есть свой язык поисковых запросов. Посмотреть его можно тут: yandex. ru/ya_detail. html. Совсем недавно он несколько сократился, читать тут (https://yandex.ru/support/search/query-language/qlanguage.html).
Главным отличием поиска Яндекс является географическая метка ресурсов, которая позволяет создавать и различать гео зависимые (30%) и гео независимые запросы (70%).
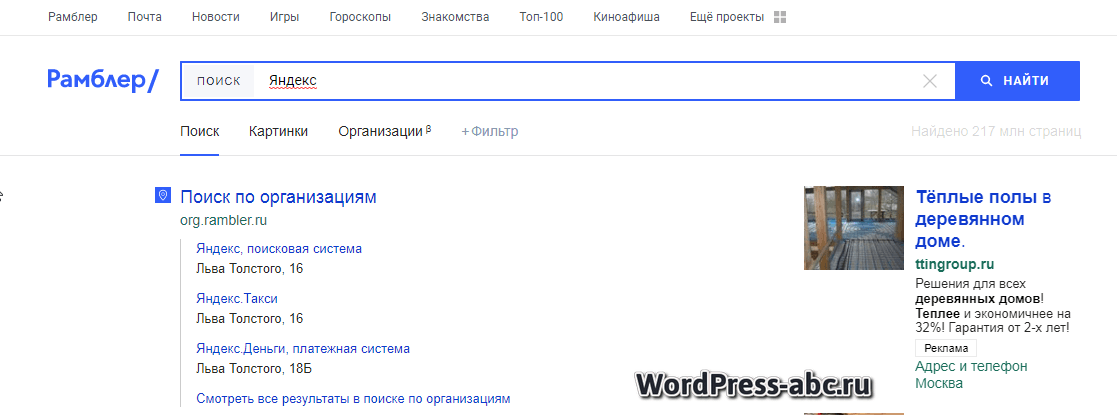
Несмотря на то, что вы найдете страницу «чистого поиска» Рамблер тут: https://r0.ru/?mobile=true, поисковой системы Рамблер НЕ существует с 2011 года.
Есть медийный портал Рамблер, с массой новостей. Есть форма поиска, которая есть не что иное, как обрезанный поиск Яндекс. Самостоятельных роботов и программ у Рамблер нет.
Страница Рамблер: https://www. rambler.ru
Стоит отметить, что остался сервис Рамблер ТОП 100, в котором участвуют (на сегодня) 169 999 сайтов. Работает он, как каталог сайтов по нему есть свой, можно сказать уникальный, поиск (https://top100.rambler.ru/).
Страница поиска есть https://go.mail.ru/
Своей поисковой системы у Mail нет. Работает некий симбиоз Google поиск на русском и Google поиск по всему миру. Часто можно встретить упоминание о не ком GoGo.ru.
Однако, огромное количество сервисов и проектов Mail, на каждом из которых есть форма поиска, позволяют поиску Mail держаться на третьем месте популярности в Рунет.
Замечу, что у Mail.ru есть свой инструмент веб-мастеров (https://webmaster.mail.ru/), где можно добавить и продвигать в Mail поиске свой ресурс.
Также не будем забывать по сервис Рейтинг Mail, https://top.mail.ru/, где можно не только отслеживать посещаемость своего сайта, но использовать поиск по рейтингу, как поиск по каталогу.
Страница поиска https://www.bing.com/?cc=ru
Данная поисковая система разработана компанией Microsoft. Она имеет свои уникальные алгоритмы индексирования и выдачи поиска.
В комплексе решаемых задач актуальность, соответствие, глубина поиска Bing уступает Google и Яндекс. Однако имеет своего преданного пользователя. Кроме основного поиска есть поиски:
Не будем забывать, что у Bing есть свой кабинет вебмастеров, который помогает продвигать ресурс в Bing выдаче. Все сервисы Bing давно имеют русскую локализацию.
Смотря на поиск и выдачу Bing, меня не покидает ощущение схожести Bing и Google поиска.
Кстати, Bing это единственный поисковик, который учитывает теги keywords в факторах ранжирования, а их отсутствие относит к негативным факторам.
У каждого поисковика, есть возможность не ждать милости, а самостоятельно добавить веб-страницу в очередь на очередной обход роботом поисковой системы. Вот список, где это можно сделать:
Общедоступной информации в Интернет настолько много, что для объективного результата поиска нужно использовать несколько поисковых систем. Мне удается находить нужную информацию, используя два поисковика, и редко картинки в Bing. Хотя, честно говоря, картинки я ищу совсем по-другому.
Объективно Google лучший поисковик для поиска по миру. Яндекс и Google.ru для поиска по России. У Бинг хорош поиск картинок. Mail поиск, просто «торчит» на всех своих социальных серверах.
К сожалению, в обзор поисковые системы интернет, не вошел поисковик DuckDuckGo https://duckduckgo.com/about с уникальным алгоритмом умного поиска, о нём в отдельной статье.
©www.wordpress-abc.ru
Как правильно выбрать название, домен, создать и продвигать сайт для региона. Читать дальше
Мобильные прокси в бизнесе, возможности и перспективы. Читать дальше
Всё, что нужно знать о ремонте и обслуживании кофемашин. Читать дальше
Как сделать ресурс удобным для пользователей при помощи доработки сайта. Читать дальше
Создание сайта на Tilda, с чего начать и как добиться успеха. Читать дальше
Секреты управления, прокачки, приобретения, бустинга игровых аккаунтов. Читать дальше
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}